2024-2-20 16:02 /
今日工作总结
1. 阅读Stable Cascade的论文Wuerstchen: An Efficient Architecture for Large-Scale Text-to-Image Diffusion Models。
根据github项目的描述,这篇论文的核心思想是将LDM的LatentSpace给缩小到24x24的尺寸,以降低其算力消耗,然后通过cascading不断放大latent representation直到还原出1024x1024的图。
单看这个思路本身没有问题,但是论文写的非常奇怪,文章写的不清不楚,注图也有问题。首先这是inference的图,这里看起来没啥问题,从左到右是inference的顺序,CBA倒过来虽然有些反骨但OK可以接受;
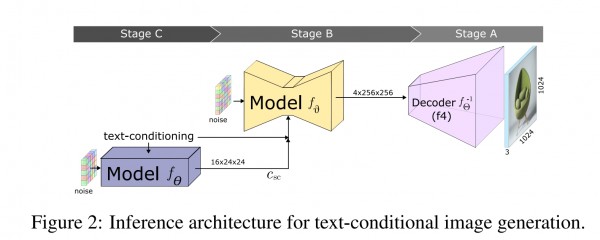
基本就是两个LDM通过cascading生成latent representation,然后再通过一个VGGAN的decoder完成图像生成。
但是到描述training的时候事情就开始变得混乱了。
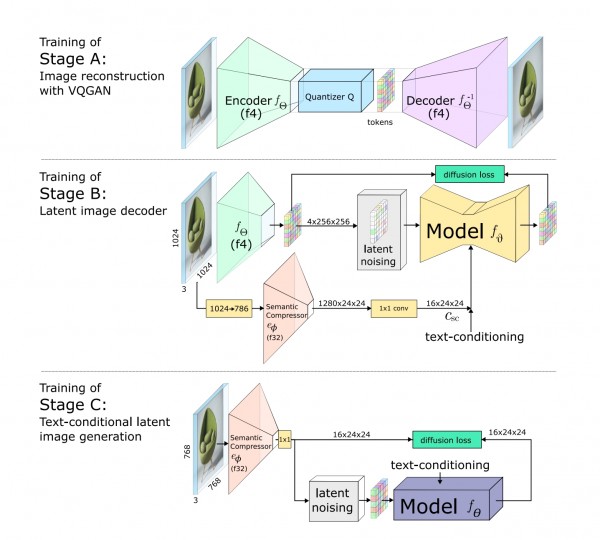
这里原文是说,ABC三个stages依次训练,先训练A这个VQGAN是常规操作,一切正常。但是到训练BC的时候逻辑和配图上都说不通。
首先是逻辑上存在先后顺序问题:按照原文的说法,如果B和C是依次训练(而不是同时)的,那么在训练B的时候会用到Sementic Compressor(一个压缩力度非常大的encoder)提供的Csc作为condition,但是文中说Csc这个东西是C提供的,而训练B的时候C还没训练?这是一个死循环。
然后是做图上:文章中B和C两个Stage都出现了Sementic Compressor这个encoder。从图上看,Csc是B阶段的Sementic Compressor提供的,和来自C的text condition进行concate后作为condition给予B,但文中又说C的作用是提供Csc,那么这个Csc到底是B自带的还是C提供的根本说不清楚。此外,既然文中说C提供Csc,那为何Stage B中又只标注一个text condition?
有的人可能会说这个Sementic Compressor只有一个,可以把C中的Sementic Compressor看作是fine-tuning,但是fine-tuning只在C这里进行吗?ABC三个stage是依次的就意味着是离散的,只针对C而不对BC进行optimize和update显然也是不对的。
不管怎么来说这个文章都有问题,还有图片的尺寸都写错了?即使是在找到的openview版本中,768写成786的错误也发生了很多次。
还有一个问题,文中说

即,之所以我们快,是因为我们用了小尺寸的condition,并通过转化的方式避开了高分辨的输入所以快。但是condition是condition,输入是输入,condition只是一个条件,最多在cross-attention的时候计算一下,输入还是256x256不变的,这不是匡人吗
这是ICLR2024 Oral。肯定是我有问题。
2. 玩了玩Lvmin新整合的webui forge。WebUI Forge的启动速度优化的很好,据传显存占用和模型加载速度有优化,明天打算看看具体是怎么优化的。
顺带尝试了SVD。初步尝试的效果是在natural image的表现上要比anime的好,虽然也没好到哪里去,就不该拿自己的照片做测试,非常古神,吓到我了。 默认的参数能够给照片中的人物肖像生成一些眨眼,镜头偏移等效果。而Anime则是直接成了不可言状的抽象图片,或者简单拉伸。有可能是没有操作好,明天继续看看。
3. 继续推进项目,做一些简单的数据统计和可视化代码工作。
1. 阅读Stable Cascade的论文Wuerstchen: An Efficient Architecture for Large-Scale Text-to-Image Diffusion Models。
根据github项目的描述,这篇论文的核心思想是将LDM的LatentSpace给缩小到24x24的尺寸,以降低其算力消耗,然后通过cascading不断放大latent representation直到还原出1024x1024的图。
单看这个思路本身没有问题,但是论文写的非常奇怪,文章写的不清不楚,注图也有问题。首先这是inference的图,这里看起来没啥问题,从左到右是inference的顺序,CBA倒过来虽然有些反骨但OK可以接受;

基本就是两个LDM通过cascading生成latent representation,然后再通过一个VGGAN的decoder完成图像生成。
但是到描述training的时候事情就开始变得混乱了。

这里原文是说,ABC三个stages依次训练,先训练A这个VQGAN是常规操作,一切正常。但是到训练BC的时候逻辑和配图上都说不通。
首先是逻辑上存在先后顺序问题:按照原文的说法,如果B和C是依次训练(而不是同时)的,那么在训练B的时候会用到Sementic Compressor(一个压缩力度非常大的encoder)提供的Csc作为condition,但是文中说Csc这个东西是C提供的,而训练B的时候C还没训练?这是一个死循环。
然后是做图上:文章中B和C两个Stage都出现了Sementic Compressor这个encoder。从图上看,Csc是B阶段的Sementic Compressor提供的,和来自C的text condition进行concate后作为condition给予B,但文中又说C的作用是提供Csc,那么这个Csc到底是B自带的还是C提供的根本说不清楚。此外,既然文中说C提供Csc,那为何Stage B中又只标注一个text condition?
有的人可能会说这个Sementic Compressor只有一个,可以把C中的Sementic Compressor看作是fine-tuning,但是fine-tuning只在C这里进行吗?ABC三个stage是依次的就意味着是离散的,只针对C而不对BC进行optimize和update显然也是不对的。
不管怎么来说这个文章都有问题,还有图片的尺寸都写错了?即使是在找到的openview版本中,768写成786的错误也发生了很多次。
还有一个问题,文中说

即,之所以我们快,是因为我们用了小尺寸的condition,并通过转化的方式避开了高分辨的输入所以快。但是condition是condition,输入是输入,condition只是一个条件,最多在cross-attention的时候计算一下,输入还是256x256不变的,这不是匡人吗
这是ICLR2024 Oral。肯定是我有问题。
2. 玩了玩Lvmin新整合的webui forge。WebUI Forge的启动速度优化的很好,据传显存占用和模型加载速度有优化,明天打算看看具体是怎么优化的。
顺带尝试了SVD。初步尝试的效果是在natural image的表现上要比anime的好,虽然也没好到哪里去,就不该拿自己的照片做测试,非常古神,吓到我了。 默认的参数能够给照片中的人物肖像生成一些眨眼,镜头偏移等效果。而Anime则是直接成了不可言状的抽象图片,或者简单拉伸。有可能是没有操作好,明天继续看看。
3. 继续推进项目,做一些简单的数据统计和可视化代码工作。