2024-2-21 15:39 /
今日工作总结
1. 阅读论文Control Color: Multimodal Diffusion-based Interactive Image Colorization.
上周五S-Lab新放出的一篇文章,和之前喵喵发的那篇[1](还没读)有一点像,做的都是自然图像的re-colorization。这篇的卖点在于multi-model + mixture correction.
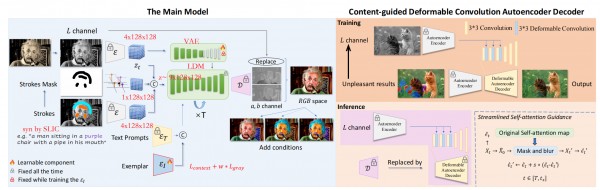
Training分为两个阶段: Main model + Content-guided Deformable Convolution Autoencoder Decoder.
在训练Main model的时候,输入是①一张图片的L channel②一张在L channel上加了synthetized color stroke(通过SLIC模拟)的图片和③color stroke自身的bi-mask. ①②的latent variable和downsampled的③进行concat后作为LDM的input noise, 重建的结果的ab通道+①作为中间结果。
之后训练Content-guided Deformable Convolution Autoencoder Decoder. 这个是对VAE的Decoder使用Deformable Convolution进行微调,使用的是监督学习Conceptual Loss. 然后Inference的时候用这个SFT后的D。
文章的其中一个卖点是multi-model,上述的Main model training只包含了stroke condition这么一个情况,还包括比较常见的text(用CLIP)和image ref(还是CLIP)做输入的情况。值得注意的是文中说用ref的时候由于不属于Supervised的情况所以用了一个叫做contextual loss的object. 这个还是比较有意思的。
文章的另一个卖点是能够对mixture和overflow的进行correction. 具体的方法是把attention map中的saliency提取出来,然后把交界处OOD的atten部分根据周围颜色重新进行上色,这个方法还是有些机智的。
目前demo还没有放出来,等后面看看实测效果。
https://zhexinliang.github.io/Control_Color/
2. 写paper的abstract和introduction部分。初步计划是先把能写的地方写了,在写的过程中对当然的进度和方向做一个拟合,规划后面进行的实验。
3. 测试了WebUI-Forge中的SVD和Pika的视频生成功能。SVD仅能对部分图片的背景进行移动;Pika的表现比SVD要好一些,但会让全图模糊起来,也达不到Live2D的效果。

好像bgm连gif都不能放.. 寄
4. 看WebUI源码。
[1] Liu, Hanyuan, et al. "Video Colorization with Pre-trained Text-to-Image Diffusion Models." arXiv preprint arXiv:2306.01732 (2023).
1. 阅读论文Control Color: Multimodal Diffusion-based Interactive Image Colorization.
上周五S-Lab新放出的一篇文章,和之前喵喵发的那篇[1](还没读)有一点像,做的都是自然图像的re-colorization。这篇的卖点在于multi-model + mixture correction.

Training分为两个阶段: Main model + Content-guided Deformable Convolution Autoencoder Decoder.
在训练Main model的时候,输入是①一张图片的L channel②一张在L channel上加了synthetized color stroke(通过SLIC模拟)的图片和③color stroke自身的bi-mask. ①②的latent variable和downsampled的③进行concat后作为LDM的input noise, 重建的结果的ab通道+①作为中间结果。
之后训练Content-guided Deformable Convolution Autoencoder Decoder. 这个是对VAE的Decoder使用Deformable Convolution进行微调,使用的是监督学习Conceptual Loss. 然后Inference的时候用这个SFT后的D。
文章的其中一个卖点是multi-model,上述的Main model training只包含了stroke condition这么一个情况,还包括比较常见的text(用CLIP)和image ref(还是CLIP)做输入的情况。值得注意的是文中说用ref的时候由于不属于Supervised的情况所以用了一个叫做contextual loss的object. 这个还是比较有意思的。
文章的另一个卖点是能够对mixture和overflow的进行correction. 具体的方法是把attention map中的saliency提取出来,然后把交界处OOD的atten部分根据周围颜色重新进行上色,这个方法还是有些机智的。
目前demo还没有放出来,等后面看看实测效果。
https://zhexinliang.github.io/Control_Color/
2. 写paper的abstract和introduction部分。初步计划是先把能写的地方写了,在写的过程中对当然的进度和方向做一个拟合,规划后面进行的实验。
3. 测试了WebUI-Forge中的SVD和Pika的视频生成功能。SVD仅能对部分图片的背景进行移动;Pika的表现比SVD要好一些,但会让全图模糊起来,也达不到Live2D的效果。

好像bgm连gif都不能放.. 寄
4. 看WebUI源码。
[1] Liu, Hanyuan, et al. "Video Colorization with Pre-trained Text-to-Image Diffusion Models." arXiv preprint arXiv:2306.01732 (2023).