#1 - 2022-3-30 13:38
冈崎羽未鹰原汐 (二阶堂芽爱 小河坂青空)
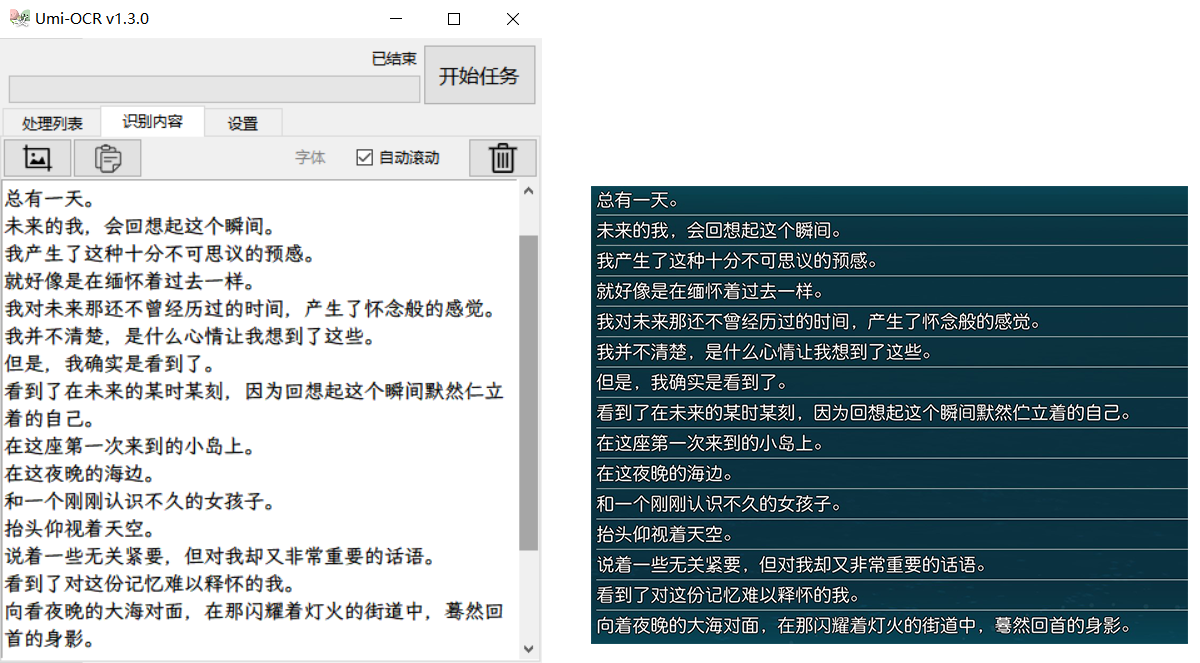
Umi-OCR 批量文字识别工具
这是一个适用于 Win10 x64 平台的离线OCR文字识别软件。支持截屏识别、粘贴图片,支持批量导入本地图片,将OCR结果输出到软件面板或本地文件。
项目地址:https://github.com/hiroi-sora/Umi-OCR
2022.11.4 更新v1.3.1版本:
· 修Bug:解决截图快捷键几率失效、录制不正确等Bug。
· 新功能:添加开机自启,桌面快捷方式,开始菜单快捷方式。
· 新功能:截图时隐藏窗口。
· 优化:`横排-合并多行-自然段` 优化逻辑,支持0~2全角空格首行缩进。
2022.9.29 更新v1.3.0版本:
· 框选截屏:即时截屏,框选想要的区域,调用OCR。
· 系统托盘:可将软件最小化到系统托盘区隐藏。
· 进程常驻:省去零碎任务的初始化时间。截图识别/剪贴板识别的耗时比前代减少50%以上。
· 文本块后处理:智能匹配并合并同一段落不同行的文字。可识别自然段。支持对竖排文本的排序和整理。
· 重制UI:各功能按钮及参数配置页有了更直观的UI,鼠标悬停可显示提示框。
· 自定义字体:软件输出面板的字体样式、大小可修改。
本来只是我一时兴起写的娱乐性质的小软件,不知不觉已经2.4k⭐了。经过几个月的迭代,尤其是9月份的爆肝,她的功能越来越丰富,成长得越来越完善。不少我最初根本没有预想的功能,也在用户的要求下加入了项目。总之挺感慨
惯例,夏兜镇楼:
==========以==下==原==贴==================
"为了管理几千张图片,写了个批量离线文字识别(OCR)软件"
我喜欢玩游戏或看番的时候截图,像拍摄下旅途的风景一样,以后翻看是一份美好的回忆。不知不觉已经积累了 7000 9000 10000 多张。带来了一个问题,如果想根据某段台词找到某张截图需要一张张翻找,很麻烦。
于是就写了个批量文字识别软件,把图片译为文本。然后直接在文本中Ctrl+f,很方便。
本软件拥有专门针对视频截图和游戏截图特化的功能:忽略区域。可以屏蔽掉视频右上角水印和游戏的UI,输出干干净净的台词文本。
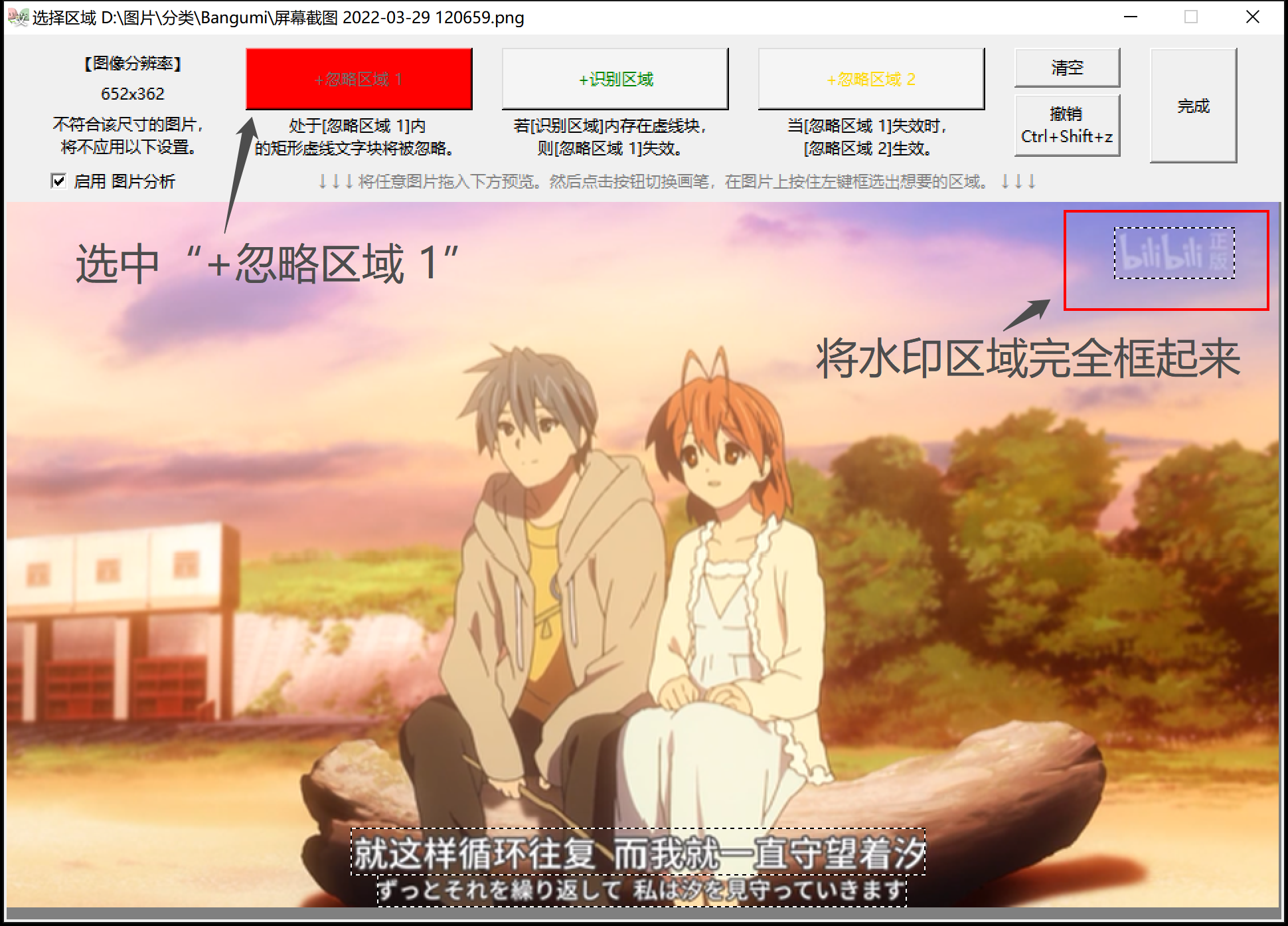
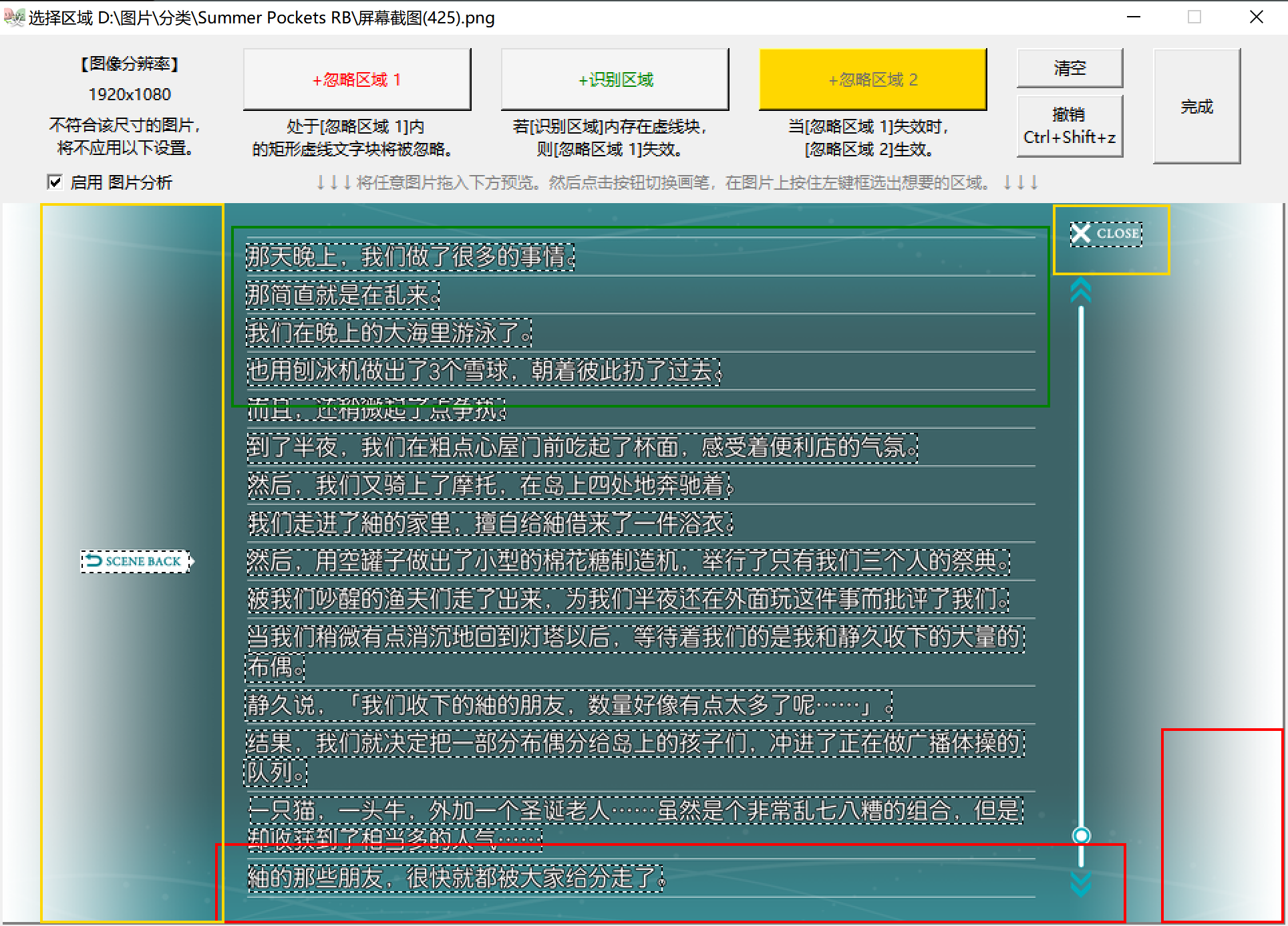
除了上述简单用法外,还有配置“条件判断双重忽略区域”的进阶功能,专门针对批量处理Galgame截图,能有效地清除“对话模式”和“历史模式”这两种界面下的不同UI。
如果你有将本地图片转为文字的需求,如果你有大量视频、游戏、漫画、三次元照片想建立文本索引以方便查找,如果你有一堆小说截图想转换为文本——欢迎尝试本软件。
识别引擎是离线 PaddleOCR ,无需联网。本软件无需安装,解压即用。自带中文+日文识别库,支持添加别国语言的 Paddle 官方模型或自己训练的模型,详见项目页面。
下载地址及详细使用说明:https://github.com/hiroi-sora/Umi-OCR
As you like my pleasure.
这是一个适用于 Win10 x64 平台的离线OCR文字识别软件。支持截屏识别、粘贴图片,支持批量导入本地图片,将OCR结果输出到软件面板或本地文件。
项目地址:https://github.com/hiroi-sora/Umi-OCR
2022.11.4 更新v1.3.1版本:
· 修Bug:解决截图快捷键几率失效、录制不正确等Bug。
· 新功能:添加开机自启,桌面快捷方式,开始菜单快捷方式。
· 新功能:截图时隐藏窗口。
· 优化:`横排-合并多行-自然段` 优化逻辑,支持0~2全角空格首行缩进。
2022.9.29 更新v1.3.0版本:
· 框选截屏:即时截屏,框选想要的区域,调用OCR。
· 系统托盘:可将软件最小化到系统托盘区隐藏。
· 进程常驻:省去零碎任务的初始化时间。截图识别/剪贴板识别的耗时比前代减少50%以上。
· 文本块后处理:智能匹配并合并同一段落不同行的文字。可识别自然段。支持对竖排文本的排序和整理。
· 重制UI:各功能按钮及参数配置页有了更直观的UI,鼠标悬停可显示提示框。
· 自定义字体:软件输出面板的字体样式、大小可修改。
本来只是我一时兴起写的娱乐性质的小软件,不知不觉已经2.4k⭐了。经过几个月的迭代,尤其是9月份的爆肝,她的功能越来越丰富,成长得越来越完善。不少我最初根本没有预想的功能,也在用户的要求下加入了项目。总之挺感慨
惯例,夏兜镇楼:
==========以==下==原==贴==================
"为了管理几千张图片,写了个批量离线文字识别(OCR)软件"
我喜欢玩游戏或看番的时候截图,像拍摄下旅途的风景一样,以后翻看是一份美好的回忆。不知不觉已经积累了 7000 9000 10000 多张。带来了一个问题,如果想根据某段台词找到某张截图需要一张张翻找,很麻烦。
于是就写了个批量文字识别软件,把图片译为文本。然后直接在文本中Ctrl+f,很方便。
本软件拥有专门针对视频截图和游戏截图特化的功能:忽略区域。可以屏蔽掉视频右上角水印和游戏的UI,输出干干净净的台词文本。
除了上述简单用法外,还有配置“条件判断双重忽略区域”的进阶功能,专门针对批量处理Galgame截图,能有效地清除“对话模式”和“历史模式”这两种界面下的不同UI。
如果你有将本地图片转为文字的需求,如果你有大量视频、游戏、漫画、三次元照片想建立文本索引以方便查找,如果你有一堆小说截图想转换为文本——欢迎尝试本软件。
识别引擎是离线 PaddleOCR ,无需联网。本软件无需安装,解压即用。自带中文+日文识别库,支持添加别国语言的 Paddle 官方模型或自己训练的模型,详见项目页面。
下载地址及详细使用说明:https://github.com/hiroi-sora/Umi-OCR
As you like my pleasure.
至于win7,我没测过支持不支持。反正python相关的主界面模块肯定是没问题(大不了换成py3.8版本),但c++的PaddleOCR引擎不保证能跑起来。不过,一些可能依赖win10的运行库我也已经扔到发行版里面去了,也许能在缺失这些库的系统上跑起来?帮我试试?
隔壁某些采用PaddleOCR引擎的天若OCR开源版本也更新了win7支持,所以理论上是没有阻碍的。
下载好相应的 dll 文件后,又报错:
win7 想要跑起来得换 py3.8,py3.9 以上不支持 win7 运行。后面还有没有坑就不知道了
另外我的意思不是实时识别,是把一个下载好的视频(尤其是古老的内嵌字幕的动画)识别出有字幕的帧并输出成图片,然后批量提取字幕出来,把内嵌的字幕转换成外挂字幕。你的这个工具简单易用,更好上手,我实际体验了之后感觉可行。
这个软件的定位只是“转换”;没有“搜索”的功能。用记事本或者vscode来在文本中搜索吧
(当然也想过做个图片浏览器的机能,软件里可以搜索文本、预览对应的图片。不过好像没太大必要?
pdf转文字有很多方案,比如OCRmyPDF。网上也能搜到各种在线工具~~这些工具可以提取文字在原文档中的位置,或干脆嵌入原文档,让你可以在图片pdf里面ctrl+f。
当然,如果只想生成纯文本,我的软件应该也挺好用的